
Moving your infrastructure into the cloud comes with great benefits to availability and scaling, but nothing comes without a cost. Navigating the complexities of cloud deployment while avoiding unnecessary expenses can be a significant challenge.
Getting an application up and running on the cloud is a complex task. The applications might just require an EC2 Instance to run or a full fledged infrastructure with Network, Kubernetes Cluster, Databases etc. Configuring the applications correctly and deploying them to run on the cloud can often be time-consuming and challenging. Its even more challenging to ensure its availability to the users 24/7. Application usage may peak during the day when most of the compute is required to serve users, while usage may drop significantly during the night. Striking the right balance between providing sufficient compute and optimising costs can be challenging.
Recognising the potential challenges of scaling Kubernetes Cluster’s Compute, we, at Kapstan, chose to address this issue proactively. Our containers were already running on Kubernetes (AWS EKS with managed node groups). As we explored potential solutions to these challenges, we initially turned to Cluster Autoscaler, which addressed some of our compute scaling issues but proved to be a partial solution. Subsequently, when faced with issues while using Cluster Autoscaler, we discovered Karpenter, which came to our rescue.
In this post, we offer an overview of popular compute scaling solutions that exist for Kubernetes, i.e. Cluster Autoscaler and Karpenter. We delve into the problems we encountered while configuring these solutions, explain why we transitioned from Cluster Autoscaler to Karpenter, and detail how it helped us optimize our cloud costs. Our post concludes with a demonstration that deploys both Cluster Autoscaler and Karpenter on an AWS EKS cluster, highlighting why Karpenter surpasses Cluster Autoscaler.
Cluster Autoscaler
In an EKS environment, Cluster Autoscaler enables the spawning of new EC2 instances by identifying unscheduled pods within the EKS cluster. It achieves this by increasing the desired number of instances in Auto Scaling Groups associated with the EC2 instances. The diagram below illustrates how Cluster Autoscaler scales nodes on EKS.
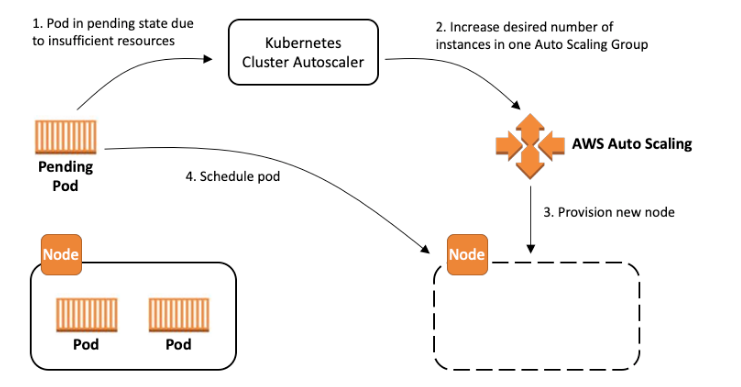
Scaling Up: Cluster Autoscaler expands the size of the EKS cluster when unscheduled pods cannot be accommodated on existing nodes due to insufficient resources. It checks for these unschedulable pods approximately every 10 seconds by default. When an unschedulable pod is detected, Cluster Autoscaler spawns a new node with specifications similar to existing nodes and schedules the pods on those nodes.
Scaling Down: Cluster Autoscaler reduces the size of the cluster when specific nodes consistently exhibit low resource utilization over an extended period. Nodes operating with minimal resource usage over time are marked as unnecessary. If no scale-up is required, Cluster Autoscaler checks for unneeded nodes approximately every 10 seconds. If unneeded nodes are detected, it waits for 10 minutes to confirm that the node remains unneeded before terminating it. This process scales down the cluster size.
Issues Faced with Cluster Autoscaler
While Cluster Autoscaler provided our EKS cluster with autoscaling capabilities, it encountered certain limitations.
Volume Node Affinity Conflict
One major challenge we encountered with Cluster Autoscaler was its inability to schedule certain unscheduled pods. Upon further investigation, we discovered that statefulset pods required access to EBS Volume Storage. Persistent EBS Volumes in AWS have node affinity, which means the node accessing the volume needed to be within the same AWS zone. However, a node running stateful pods was terminated as part of scheduled termination. When Cluster Autoscaler triggered the spawning of a new node, it occurred in a different zone, leading to a volume node affinity conflict and leaving the stateful pods unscheduled.
This issue could be resolved by provisioning multiple autoscaling groups across all availability zones. This approach would make Cluster Autoscaler zone-aware and allow it to provision nodes in the correct availability zone. However, this solution introduces the challenge of managing multiple Auto Scaling Groups for each zone.
Unsatisfactory EC2 Compute Costs

Despite our application’s traffic not experiencing a significant spike, our EC2 compute costs almost doubled within just two months. Cluster Autoscaler was not able to provision nodes based on the compute required for a pod to run, it just identified an unscheduled pod and replicated an existing node from the node group with identical specifications. This resulted in inefficient bin packing and workload consolidation, causing us to pay for underutilised compute and had adverse effects on our compute costs.
Faced with these challenges from Cluster Autoscaler, we began exploring alternative compute autoscaling solutions. This exploration led us to the discovery of Karpenter.
Karpenter

Karpenter was developed to overcome the limitations of existing Kubernetes autoscaling solutions such as Cluster Autoscaler. It introduces a smarter, efficient, and customizable approach to node provisioning and autoscaling. Karpenter monitors unscheduled pods, spawns new nodes, and optimizes scheduling for cost efficiency.
For example, Karpenter can terminate multiple smaller nodes and consolidate pods onto a single, optimally provisioned node. This efficiency is achieved by monitoring Kubernetes events and issuing commands to the cloud provider’s compute service. Below, we outline several aspects in which Karpenter outperforms Cluster Autoscaler.
Elimination of Multiple Autoscaling Groups Management: Karpenter eliminates the need to manage numerous autoscaling groups, streamlining the experience while offering enhanced flexibility and workload distribution. It is zone-aware and capable of provisioning pods in required zones.
Intelligent Node Allocation: Karpenter intelligently allocates nodes based on precise workload requirements, optimizing resource allocation. By considering the CPU and memory requests of unscheduled Pods, Karpenter spawns nodes that align with pod requirements. This approach reduces the likelihood of provisioning nodes that are too large or too small, thereby optimizing costs while maintaining high system availability.
Versatile Node Configuration: Karpenter supports diverse node configurations based on instance types. Users can mix instances with varying compute power, allowing Karpenter to select the instance type that best matches pod requirements.
Enhanced Scaling and Scheduling: Karpenter streamlines and enhances scaling by promptly launching new nodes as demand increases. This dynamic scaling, based on continuous monitoring of workload and resource utilization, ensures optimal resource allocation and prevents performance bottlenecks during peak usage.
The major features in Karpenter that helped us at Kapstan are the following:
Scheduling
Karpenter offers a finer degree of control over the placement of unscheduled pods compared to Cluster Autoscaler. It supports the addition of constraints to pods, enabling specific placement on zones or nodes based on use cases. For instance, we configured Karpenter to prefer certain node groups during auto-scaling. Additionally, we distributed similar pods across different nodes, enhancing fault tolerance in case of node failures and ensuring even pod distribution across nodes. These configurations significantly improved the fault tolerance and high availability of our cluster.
It also provides ability to schedule pods only on the certain special nodes. For example, consider a use case where there are certain pods that do some Machine Learning related task and might require GPU intensive instance type, in that case one can configure Karpenter in a way that it, only schedules the required pods on those compute intensive nodes. And after the pods are done with their tasks, Karpenter will de-provision them so that other pods don’t use those nodes.
Workload Consolidation
Karpenter’s Workload Consolidation feature is advanced than what we see in cluster autoscaler. While cluster autoscaler can identify redundant nodes with less number of pods and consolidate multiple such nodes into a single one, it can only do it on the nodes that have same memory and cpu.
Each Auto Scaling Group should be composed of instance types that provide approximately equal capacity. For example, ASG “xlarge” could be composed of m5a.xlarge, m4.xlarge, m5.xlarge, and m5d.xlarge instance types, because each of those provide 4 vCPUs and 16GiB RAM. Separately, ASG “2xlarge” could be composed of m5a.2xlarge, m4.2xlarge, m5.2xlarge, and m5d.2xlarge instance types, because each of those provide 8 vCPUs and 32GiB RAM.
where as Karpenter intelligently consolidates workloads onto minimal, cost-effective instances while considering pod resource and scheduling constraints. For example in the default configuration it can choose an instance of any size among c, m, r instance category of aws ec2 instances, some examples would be
| c6g.medium | 1 vCPU, 2 GiB Memory |
| m7g.large | 2 vCPUs, 8 GiB Memory |
| r6g.xlarge | 4 vCPUs, 32 GiB Memory |
This enables Karpenter to perform way better bin packing than cluster autoscaler. It also aggressively monitors cluster workloads to identify opportunities for compute capacity consolidation, optimising cost efficiency and node utilisation. It’s important to configure CPU and Memory requests for pods, for this feature to function effectively. These configurations guide Karpenter in selecting the appropriate instance type for scheduled pods.
Resolving Major Issues
Karpenter’s ability to look at the pod requirements and schedule them in the required zones and nodes helped us resolve the volume node affinity conflict we had faced for statefulset pods whose nodes and volumes needed to be in the same region.
Workload Consolidation feature of Karpenter has been a game changer for us, after provisioning Karpenter in our EKS cluster we saw 50% drop in our EC2 compute costs.
Game-Changing Cost Efficacy
As mentioned earlier after performing the most optimal workload consolidation based on pods compute requests, Karpenter goes one step ahead and tries to find out the cheapest instance among all the instance types that would fit the requirement. It uses the price-capacity-optimised allocation strategy in order to get the most cost optimal instance type, that would be able to fit the unscheduled pods.

The EC2 cost history graph above demonstrates how the adoption of Cluster Autoscaler resulted in a nearly double cost within two months, despite application usage remaining relatively stable. Transitioning to Karpenter reversed this trend. By the end of June, with Karpenter provisioned in our cluster, our costs dropped by nearly 50%, keeping it stable, unlike the fluctuations observed with Cluster Autoscaler, Karpenter consistently delivered efficient cost optimization.
Demo
Here is a link to a terraform repository that demonstrates intelligent autoscaling of Karpenter in comparison to cluster autoscaler. You can see how Cluster Autoscaler just replicates an extra node with the same specifications of the existing node, while Karpenter chooses a smaller and cheaper node, just right to fit the requirements of unscheduled pods.
Conclusion
While Cluster Autoscaler initially provided a glimpse of autoscaling capabilities, its limitations in resource optimization and intelligent scaling quickly became apparent. Karpenter offered us a meticulous approach to pod scheduling, efficient node allocation, and scaling like no other, Karpenter transformed our cloud experience at Kapstan.
We hope this blog has been helpful to you and would help you get around challenges, that you face while creating a scalable and cost efficient Kubernetes Cluster.
Our team is working on making cloud deployments smooth and scalable. With Kapstan, setting up an AWS EKS cluster using Karpenter is a breeze, it just takes you a few button clicks, and you get a highly available and cost optimal Kubernetes cluster. We are building Kapstan so that you don’t have to worry about Infrastructure and Application deployment nightmares. Notably, Kapstan deployed infrastructure is also SOC 2 compliant, ensuring we meet your security requirements with confidence. Get in touch at hi@kapstan.io – let’s start your journey to simple, fast and secure cloud practices together.
